 公众号
公众号DeepSeek-R1技术解码:如何实现大模型推理能力的提升?
2025-02-11 23:10:05
- +1 你赞过了
1月20日,幻方量化旗下AI公司深度求索(DeepSeek)发布了新一代开源大模型DeepSeek-R1。作为一款专注于推理能力的AI大模型,DeepSeek-R1凭借着成本低、推理能力强等优势,在人工智能领域掀起了千层巨浪,引起了人们的广泛关注与讨论。
DeepSeek-R1的成功,让我们更加清晰地认识到推理能力在当下人工智能发展中的重要地位。那么,究竟什么是大模型的推理?DeepSeek-R1推理能力强的原因又是什么呢。
如何理解推理大模型?
要解答这些问题,首先需明确大模型中的推理概念。推理,本质上是从已知判断(前提)推导出新判断(结论)的思维形式。比如,“法国的首都是什么?” 这类事实性问题的回答,并不涉及推理过程。而像 “若火车以每小时60公里的速度行驶,3小时后它会行驶多远?” 这样的问题,则需要进行一定的简单推理。在得出答案前,模型需识别距离、速度与时间之间的关系。
当前,多数大模型已具备基本的推理能力。因此,当提及推理大模型时,通常指的是那些在解决难题、谜语以及数学证明等更为复杂的推理任务中表现出色的大模型。
在推理大模型中,中间步骤的呈现方式主要有两种。其一,这些中间步骤会被明确地包含在模型的响应之中,如DeepSeek会展示思考过程,然后再给出答案;其二,中间步骤不会展示给用户,而是直接给出答案。
推理大模型擅长复杂的任务,例如解决难题,高级数学问题和具有挑战性的编码任务。但是,对于诸如摘要,翻译或基于知识的问题回答之类的简单任务,它们不是必需的。
实际上,对所有事物使用推理大模型可能效率低下且成本高昂。例如,推理大模型通常使用起来更昂贵,更冗长,有时由于 “过度思考” 而更容易出错。
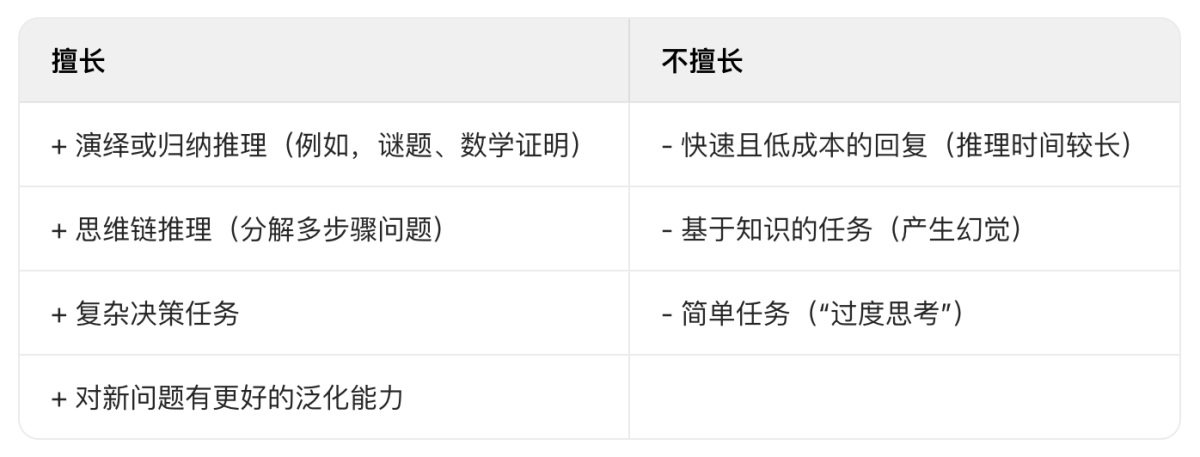
上图:推理大模型的主要优势和局限性
改进推理模型的四种策略
值得一提的是,在AI领域拥有超过十年经验的研究者Sebastian Raschka介绍了改进推理模型的4种主要方法。
1)推理时间扩展
提高大模型推理能力的一种方法是推理时间扩展。该术语可以具有多种含义,但是在这种情况下,它是指在推理过程中增加计算资源以提高输出质量。
一个粗略的类比是,当给予更多时间思考复杂问题时,人类往往会产生更好的反应。同样,我们可以应用一些技巧,鼓励大模型在回答问题时更多地“思考”。
推理时间扩展的一个直接方法是巧妙的提示工程。一个典型的例子是思维链 (CoT) 提示,其中像 “一步一步思考” 这样的短语包含在输入提示中。这鼓励模型生成中间推理步骤,而不是直接跳到最终答案,这通常可以在更复杂的问题上获得更准确的结果。
上述思维链方法可以被视为推理时间缩放,因为它通过生成更多的输出令牌使推理更加昂贵。
另一种推理时间扩展方法是使用投票和搜索策略。一个简单的例子是多数投票,让大模型生成多个答案,然后通过多数投票选择正确的答案。同样,可以使用集束搜索和其他搜索算法来生成更好的响应。
2) 纯强化学习 (RL)
Raschka在DeepSeek R1论文中发现的亮点之一是他们发现推理是纯强化学习 (RL) 的一种行为。
具体而言,DeepSeek开发了三种类型的R1模型。一是DeepSeek-R1-Zero,建立在DeepSeek-V3基础模型之上。与典型的RL流程不同,在RL之前应用监督微调 (SFT),DeepSeek-R1-Zero仅通过强化学习进行训练,而没有初始SFT阶段。
尽管如此,该RL过程类似于通常使用的强化学习 (RLHF) 方法,其通常应用于偏好调整大模型。
但是,DeepSeek-R1-Zero的关键区别在于它们跳过了用于指令调谐的监督微调 (SFT) 阶段。这就是为什么将其称为 “纯” RL。
对于奖励,他们没有使用根据人类偏好训练的奖励模型,而是采用了两种类型的奖励: 准确性奖励和格式奖励。其中,准确性奖励使用LeetCode编译器来验证编码答案,并使用确定性系统来评估数学响应。而格式奖励则依赖于大模型评委,以确保响应遵循预期的格式,例如将推理步骤放在标签内。
3) 监督的优化和强化学习 (SFT + RL)
DeepSeek的旗舰推理模型DeepSeek-R1,在DeepSeek-R1-Zero的基础上进行了改进,加入了额外的监督微调(SFT)和强化学习(RL),以提高其推理性能。
DeepSeek团队使用DeepSeek-R1-Zero生成所谓的 “冷启动” SFT数据。术语 “冷启动” 指的是该数据是由DeepSeek-R1-Zero产生的,其本身没有在任何监督微调 (SFT) 数据上训练。
使用这种冷启动SFT数据,DeepSeek然后通过指令微调训练模型,然后是另一个强化学习 (RL) 阶段。此RL阶段保留了DeepSeek-R1-Zero RL过程中使用的相同准确性和格式奖励。但是,他们添加了一致性奖励以防止语言混合,当模型在响应中的多种语言之间切换时,就会发生这种情况。
RL阶段之后是另一轮SFT数据收集。在此阶段,使用最新的模型检查点生成600k的思想链SFT示例,同时使用DeepSeek-V3基础模型创建了额外的200k基于知识的SFT示例。
然后将这些600k + 200k SFT样本用于指令微调DeepSeek-V3基,然后再进行最后一轮RL。在此阶段,他们再次使用基于规则的方法对数学和编码问题进行准确性奖励,而人类偏好标签则用于其他问题类型。总而言之,这与常规RLHF非常相似,除了SFT数据包含 (更多) CoT示例。除了基于人类偏好的奖励之外,RL还具有可验证的奖励。
由于额外的SFT和RL级,最终模型DeepSeek-R1随着DeepSeek-R1-Zero的推移具有明显的性能提升。
4) 纯监督微调 (SFT) 和蒸馏
DeepSeek团队还发布了通过他们称之为蒸馏的过程训练的较小模型。然而,在大模型的背景下,蒸馏不一定遵循深度学习中使用的经典知识蒸馏方法。传统上,在知识蒸馏中,较小的学生模型在较大的教师模型和目标数据集的对数上进行训练。
相反,这里的蒸馏是指在较大的大模型生成的SFT数据集上对较小的大模型,如Llama 8B和70B以及 Qwen 2.5模型(0.5B 到 32B),进行指令微调。简单来说,这些较大的大模型是DeepSeek-V3和 DeepSeek-R1的中间检查点。事实上,用于此蒸馏过程的SFT数据与用于训练DeepSeek-R1的数据集相同。
DeepSeek为什么要开发蒸馏模型?Raschka认为,有两个关键原因::一是较小的模型效率更高。这意味着它们运行起来更便宜,但它们也可以在低端硬件上运行。二是纯SFT的案例研究。这些蒸馏模型作为一个基准,展示纯监督微调 (SFT) 在没有强化学习的情况下可以让模型走多远。
下表比较了这些蒸馏模型与其他流行模型以及DeepSeek-R1-Zero和DeepSeek-R1的性能。
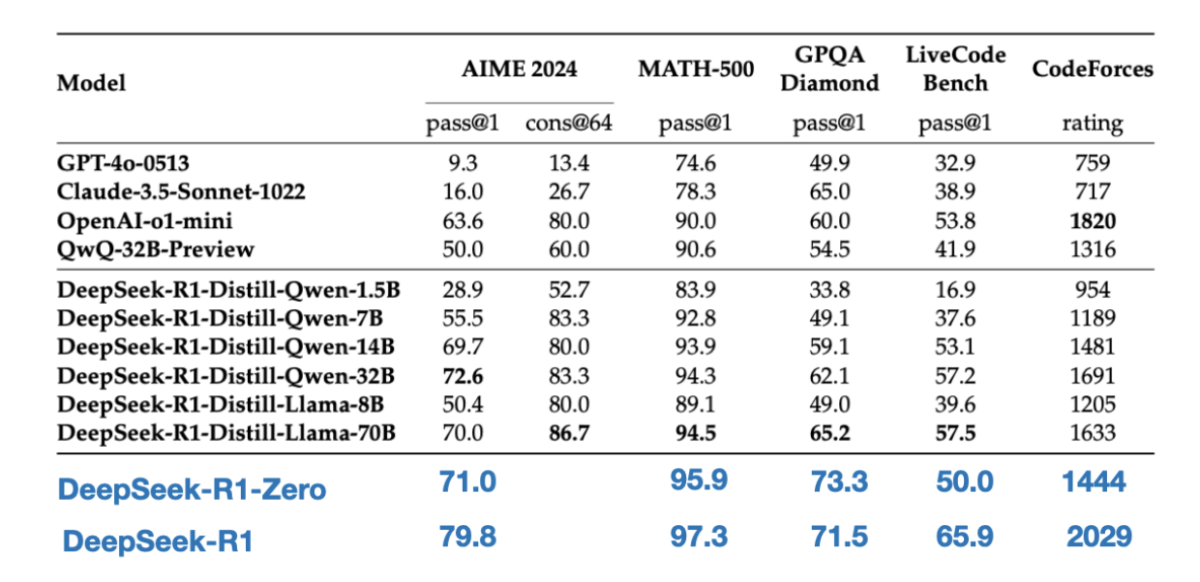
蒸馏模型明显弱于DeepSeek-R1模型,但与 DeepSeek-R1-Zero相比,它们却出奇地强大,尽管规模小了几个数量级。
值得一提的是,DeepSeek团队测试了DeepSeek-R1-Zero 中出现的新兴推理行为是否也会出现在较小的模型中。为了研究这一点,他们将DeepSeek-R1-Zero中相同的纯RL方法直接应用于Qwen-32B。
实验的结果总结在下表中,其中QwQ-32B-Preview作为基于Qwen团队开发的Qwen 2.5 32B的参考推理模型。
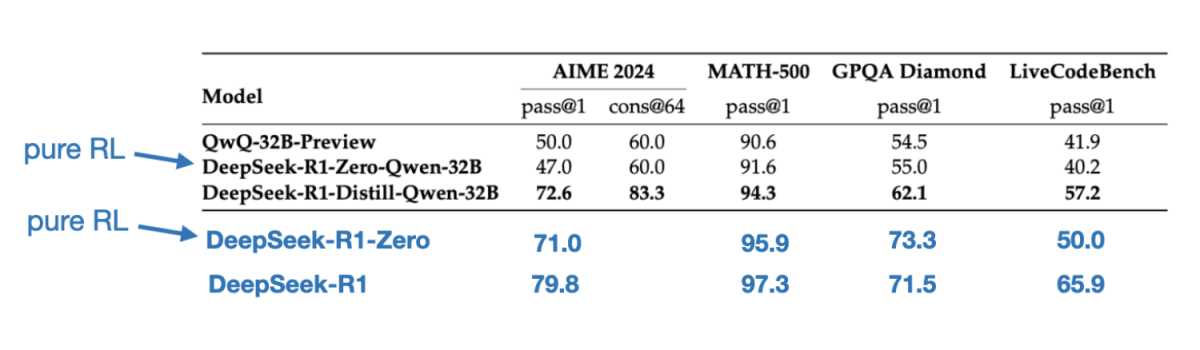
结果表明,对于较小的模型,蒸馏比纯强化学习更有效。这与以下观点一致:单靠强化学习可能不足以在这种规模的模型中产生强大的推理能力,而在使用小型模型时,对高质量推理数据进行SFT可能是更有效的策略。
可以说,这四种改进推理模型的方法,从不同角度为提升大模型推理能力提供了可行路径。推理时间扩展通过优化推理过程中的计算资源与提示方式,增强模型思考深度;纯强化学习另辟蹊径,跳过传统监督微调初始阶段,以独特奖励机制训练模型;监督的优化和强化学习相结合的方式,在已有模型基础上多次微调与强化,逐步提升性能;纯监督微调与蒸馏则聚焦于小模型的高效性与对纯SFT潜力的挖掘。
写在最后:
推理大模型不仅是解决复杂问题、推动各领域技术创新的关键力量,更是引领人工智能从基础应用迈向深度智能的核心驱动力。面向未来,随着技术的不断发展,我们有理由相信将有更多性能出色的大模型,在更多领域绽放光彩,推动人工智能技术迈向新的高度。











yu
最新资讯
热门视频
新品评测
 X
X

 微博认证登录
微博认证登录
 QQ账号登录
QQ账号登录
 微信账号登录
微信账号登录



































